Interpreter (computing)
| Program execution |
|---|
General concepts |
|
Types of code |
|
Compilation strategies |
|
Notable runtimes |
|
Notable compilers & toolchains |
|
In computer science, an interpreter is a computer program that directly executes, i.e. performs, instructions written in a programming or scripting language, without requiring them previously to have been compiled into a machine language program. An interpreter generally uses one of the following strategies for program execution:
parse the source code and perform its behavior directly;- translate source code into some efficient intermediate representation and immediately execute this;
- explicitly execute stored precompiled code[1] made by a compiler which is part of the interpreter system.
Early versions of Lisp programming language and Dartmouth BASIC would be examples of the first type. Perl, Python, MATLAB, and Ruby are examples of the second, while UCSD Pascal is an example of the third type. Source programs are compiled ahead of time and stored as machine independent code, which is then linked at run-time and executed by an interpreter and/or compiler (for JIT systems). Some systems, such as Smalltalk and contemporary versions of BASIC and Java may also combine two and three.[2] Interpreters of various types have also been constructed for many languages traditionally associated with compilation, such as Algol, Fortran, Cobol and C/C++.
While interpretation and compilation are the two main means by which programming languages are implemented, they are not mutually exclusive, as most interpreting systems also perform some translation work, just like compilers. The terms "interpreted language" or "compiled language" signify that the canonical implementation of that language is an interpreter or a compiler, respectively. A high level language is ideally an abstraction independent of particular implementations.
Contents
1 History
2 Compilers versus interpreters
2.1 Development cycle
2.2 Distribution
2.3 Efficiency
2.4 Regression
3 Variations
3.1 Bytecode interpreters
3.2 Threaded code interpreters
3.3 Abstract syntax tree interpreters
3.4 Just-in-time compilation
3.5 Self-interpreter
3.6 Microcode
4 Applications
5 See also
6 Notes and references
7 External links
History
Interpreters were used as early as 1952 to ease programming within the limitations of computers at the time (e.g. a shortage of program storage space, or no native support for floating point numbers). Interpreters were also used to translate between low-level machine languages, allowing code to be written for machines that were still under construction and tested on computers that already existed.[3] The first interpreted high-level language was Lisp. Lisp was first implemented in 1958 by Steve Russell on an IBM 704 computer. Russell had read John McCarthy's paper, and realized (to McCarthy's surprise) that the Lisp eval function could be implemented in machine code.[4] The result was a working Lisp interpreter which could be used to run Lisp programs, or more properly, "evaluate Lisp expressions".
Compilers versus interpreters
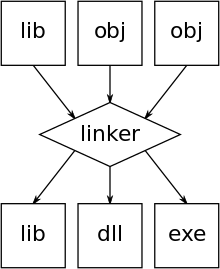
An illustration of the linking process. Object files and static libraries are assembled into a new library or executable
Programs written in a high level language are either directly executed by some kind of interpreter or converted into machine code by a compiler (and assembler and linker) for the CPU to execute.
While compilers (and assemblers) generally produce machine code directly executable by computer hardware, they can often (optionally) produce an intermediate form called object code. This is basically the same machine specific code but augmented with a symbol table with names and tags to make executable blocks (or modules) identifiable and relocatable. Compiled programs will typically use building blocks (functions) kept in a library of such object code modules. A linker is used to combine (pre-made) library files with the object file(s) of the application to form a single executable file. The object files that are used to generate an executable file are thus often produced at different times, and sometimes even by different languages (capable of generating the same object format).
A simple interpreter written in a low level language (e.g. assembly) may have similar machine code blocks implementing functions of the high level language stored, and executed when a function's entry in a look up table points to that code. However, an interpreter written in a high level language typically uses another approach, such as generating and then walking a parse tree, or by generating and executing intermediate software-defined instructions, or both.
Thus, both compilers and interpreters generally turn source code (text files) into tokens, both may (or may not) generate a parse tree, and both may generate immediate instructions (for a stack machine, quadruple code, or by other means). The basic difference is that a compiler system, including a (built in or separate) linker, generates a stand-alone machine code program, while an interpreter system instead performs the actions described by the high level program.
A compiler can thus make almost all the conversions from source code semantics to the machine level once and for all (i.e. until the program has to be changed) while an interpreter has to do some of this conversion work every time a statement or function is executed. However, in an efficient interpreter, much of the translation work (including analysis of types, and similar) is factored out and done only the first time a program, module, function, or even statement, is run, thus quite akin to how a compiler works. However, a compiled program still runs much faster, under most circumstances, in part because compilers are designed to optimize code, and may be given ample time for this. This is especially true for simpler high level languages without (many) dynamic data structures, checks, or type-checks.
In traditional compilation, the executable output of the linkers (.exe files or .dll files or a library, see picture) is typically relocatable when run under a general operating system, much like the object code modules are but with the difference that this relocation is done dynamically at run time, i.e. when the program is loaded for execution. On the other hand, compiled and linked programs for small embedded systems are typically statically allocated, often hard coded in a NOR flash memory, as there is often no secondary storage and no operating system in this sense.
Historically, most interpreter-systems have had a self-contained editor built in. This is becoming more common also for compilers (then often called an IDE), although some programmers prefer to use an editor of their choice and run the compiler, linker and other tools manually. Historically, compilers predate interpreters because hardware at that time could not support both the interpreter and interpreted code and the typical batch environment of the time limited the advantages of interpretation.[5]
Development cycle
During the software development cycle, programmers make frequent changes to source code. When using a compiler, each time a change is made to the source code, they must wait for the compiler to translate the altered source files and link all of the binary code files together before the program can be executed. The larger the program, the longer the wait. By contrast, a programmer using an interpreter does a lot less waiting, as the interpreter usually just needs to translate the code being worked on to an intermediate representation (or not translate it at all), thus requiring much less time before the changes can be tested. Effects are evident upon saving the source code and reloading the program. Compiled code is generally less readily debugged as editing, compiling, and linking are sequential processes that have to be conducted in the proper sequence with a proper set of commands. For this reason, many compilers also have an executive aid, known as a Make file and program. The Make file lists compiler and linker command lines and program source code files, but might take a simple command line menu input (e.g. "Make 3") which selects the third group (set) of instructions then issues the commands to the compiler, and linker feeding the specified source code files.
Distribution
A compiler converts source code into binary instruction for a specific processor's architecture, thus making it less portable. This conversion is made just once, on the developer's environment, and after that the same binary can be distributed to the user's machines where it can be executed without further translation. A cross compiler can generate binary code for the user machine even if it has a different processor than the machine where the code is compiled.
An interpreted program can be distributed as source code. It needs to be translated in each final machine, which takes more time but makes the program distribution independent of the machine's architecture. However, the portability of interpreted source code is dependent on the target machine actually having a suitable interpreter. If the interpreter needs to be supplied along with the source, the overall installation process is more complex than delivery of a monolithic executable since the interpreter itself is part of what need be installed.
The fact that interpreted code can easily be read and copied by humans can be of concern from the point of view of copyright. However, various systems of encryption and obfuscation exist. Delivery of intermediate code, such as bytecode, has a similar effect to obfuscation, but bytecode could be decoded with a decompiler or disassembler.[citation needed]
Efficiency
The main disadvantage of interpreters is that an interpreted program typically runs slower than if it had been compiled. The difference in speeds could be tiny or great; often an order of magnitude and sometimes more. It generally takes longer to run a program under an interpreter than to run the compiled code but it can take less time to interpret it than the total time required to compile and run it. This is especially important when prototyping and testing code when an edit-interpret-debug cycle can often be much shorter than an edit-compile-run-debug cycle.[citation needed]
Interpreting code is slower than running the compiled code because the interpreter must analyze each statement in the program each time it is executed and then perform the desired action, whereas the compiled code just performs the action within a fixed context determined by the compilation. This run-time analysis is known as "interpretive overhead". Access to variables is also slower in an interpreter because the mapping of identifiers to storage locations must be done repeatedly at run-time rather than at compile time.[citation needed]
There are various compromises between the development speed when using an interpreter and the execution speed when using a compiler. Some systems (such as some Lisps) allow interpreted and compiled code to call each other and to share variables. This means that once a routine has been tested and debugged under the interpreter it can be compiled and thus benefit from faster execution while other routines are being developed.[citation needed] Many interpreters do not execute the source code as it stands but convert it into some more compact internal form. Many BASIC interpreters replace keywords with single byte tokens which can be used to find the instruction in a jump table. A few interpreters, such as the PBASIC interpreter, achieve even higher levels of program compaction by using a bit-oriented rather than a byte-oriented program memory structure, where commands tokens occupy perhaps 5 bits, nominally "16-bit" constants are stored in a variable-length code requiring 3, 6, 10, or 18 bits, and address operands include a "bit offset". Many BASIC interpreters can store and read back their own tokenized internal representation.
| Toy C expression interpreter |
|---|
// data types for abstract syntax tree |
An interpreter might well use the same lexical analyzer and parser as the compiler and then interpret the resulting abstract syntax tree.
Example data type definitions for the latter, and a toy interpreter for syntax trees obtained from C expressions are shown in the box.
Regression
Interpretation cannot be used as the sole method of execution: even though an interpreter can itself be interpreted and so on, a directly executed program is needed somewhere at the bottom of the stack because the code being interpreted is not, by definition, the same as the machine code that the CPU can execute.[6][7]
Variations
Bytecode interpreters
There is a spectrum of possibilities between interpreting and compiling, depending on the amount of analysis performed before the program is executed. For example, Emacs Lisp is compiled to bytecode, which is a highly compressed and optimized representation of the Lisp source, but is not machine code (and therefore not tied to any particular hardware). This "compiled" code is then interpreted by a bytecode interpreter (itself written in C). The compiled code in this case is machine code for a virtual machine, which is implemented not in hardware, but in the bytecode interpreter. Such compiling interpreters are sometimes also called compreters.[8][9] In a bytecode interpreter each instruction starts with a byte, and therefore bytecode interpreters have up to 256 instructions, although not all may be used. Some bytecodes may take multiple bytes, and may be arbitrarily complicated.
Control tables - that do not necessarily ever need to pass through a compiling phase - dictate appropriate algorithmic control flow via customized interpreters in similar fashion to bytecode interpreters.
Threaded code interpreters
Threaded code interpreters are similar to bytecode interpreters but instead of bytes they use pointers. Each "instruction" is a word that points to a function or an instruction sequence, possibly followed by a parameter. The threaded code interpreter either loops fetching instructions and calling the functions they point to, or fetches the first instruction and jumps to it, and every instruction sequence ends with a fetch and jump to the next instruction. Unlike bytecode there is no effective limit on the number of different instructions other than available memory and address space. The classic example of threaded code is the Forth code used in Open Firmware systems: the source language is compiled into "F code" (a bytecode), which is then interpreted by a virtual machine.[citation needed]
Abstract syntax tree interpreters
In the spectrum between interpreting and compiling, another approach is to transform the source code into an optimized abstract syntax tree (AST), then execute the program following this tree structure, or use it to generate native code just-in-time.[10] In this approach, each sentence needs to be parsed just once. As an advantage over bytecode, the AST keeps the global program structure and relations between statements (which is lost in a bytecode representation), and when compressed provides a more compact representation.[11] Thus, using AST has been proposed as a better intermediate format for just-in-time compilers than bytecode. Also, it allows the system to perform better analysis during runtime.
However, for interpreters, an AST causes more overhead than a bytecode interpreter, because of nodes related to syntax performing no useful work, of a less sequential representation (requiring traversal of more pointers) and of overhead visiting the tree.[12]
Just-in-time compilation
Further blurring the distinction between interpreters, bytecode interpreters and compilation is just-in-time compilation (JIT), a technique in which the intermediate representation is compiled to native machine code at runtime. This confers the efficiency of running native code, at the cost of startup time and increased memory use when the bytecode or AST is first compiled. Adaptive optimization is a complementary technique in which the interpreter profiles the running program and compiles its most frequently executed parts into native code. Both techniques are a few decades old, appearing in languages such as Smalltalk in the 1980s.[13]
Just-in-time compilation has gained mainstream attention amongst language implementers in recent years, with Java, the .NET Framework, most modern JavaScript implementations, and Matlab now including JITs.[citation needed]
Self-interpreter
A self-interpreter is a programming language interpreter written in a programming language which can interpret itself; an example is a BASIC interpreter written in BASIC. Self-interpreters are related to self-hosting compilers.
If no compiler exists for the language to be interpreted, creating a self-interpreter requires the implementation of the language in a host language (which may be another programming language or assembler). By having a first interpreter such as this, the system is bootstrapped and new versions of the interpreter can be developed in the language itself. It was in this way that Donald Knuth developed the TANGLE interpreter for the language WEB of the industrial standard TeX typesetting system.
Defining a computer language is usually done in relation to an abstract machine (so-called operational semantics) or as a mathematical function (denotational semantics). A language may also be defined by an interpreter in which the semantics of the host language is given. The definition of a language by a self-interpreter is not well-founded (it cannot define a language), but a self-interpreter tells a reader about the expressiveness and elegance of a language. It also enables the interpreter to interpret its source code, the first step towards reflective interpreting.
An important design dimension in the implementation of a self-interpreter is whether a feature of the interpreted language is implemented with the same feature in the interpreter's host language. An example is whether a closure in a Lisp-like language is implemented using closures in the interpreter language or implemented "manually" with a data structure explicitly storing the environment. The more features implemented by the same feature in the host language, the less control the programmer of the interpreter has; a different behavior for dealing with number overflows cannot be realized if the arithmetic operations are delegated to corresponding operations in the host language.
Some languages have an elegant self-interpreter, such as Lisp or Prolog.[14] Much research on self-interpreters (particularly reflective interpreters) has been conducted in the Scheme programming language, a dialect of Lisp. In general, however, any Turing-complete language allows writing of its own interpreter. Lisp is such a language, because Lisp programs are lists of symbols and other lists. XSLT is such a language, because XSLT programs are written in XML. A sub-domain of meta-programming is the writing of domain-specific languages (DSLs).
Clive Gifford introduced[citation needed] a measure quality of self-interpreter (the eigenratio), the limit of the ratio between computer time spent running a stack of N self-interpreters and time spent to run a stack of N − 1 self-interpreters as N goes to infinity. This value does not depend on the program being run.
The book Structure and Interpretation of Computer Programs presents examples of meta-circular interpretation for Scheme and its dialects. Other examples of languages with a self-interpreter are Forth and Pascal.
Microcode
Microcode is a very commonly used technique "that imposes an interpreter between the hardware and the architectural level of a computer".[15] As such, the microcode is a layer of hardware-level instructions that implement higher-level machine code instructions or internal state machine sequencing in many digital processing elements. Microcode is used in general-purpose central processing units, as well as in more specialized processors such as microcontrollers, digital signal processors, channel controllers, disk controllers, network interface controllers, network processors, graphics processing units, and in other hardware.
Microcode typically resides in special high-speed memory and translates machine instructions, state machine data or other input into sequences of detailed circuit-level operations. It separates the machine instructions from the underlying electronics so that instructions can be designed and altered more freely. It also facilitates the building of complex multi-step instructions, while reducing the complexity of computer circuits. Writing microcode is often called microprogramming and the microcode in a particular processor implementation is sometimes called a microprogram.
More extensive microcoding allows small and simple microarchitectures to emulate more powerful architectures with wider word length, more execution units and so on, which is a relatively simple way to achieve software compatibility between different products in a processor family.
Applications
- Interpreters are frequently used to execute command languages, and glue languages since each operator executed in command language is usually an invocation of a complex routine such as an editor or compiler.[citation needed]
Self-modifying code can easily be implemented in an interpreted language. This relates to the origins of interpretation in Lisp and artificial intelligence research.[citation needed]
Virtualization. Machine code intended for a hardware architecture can be run using a virtual machine. This is often used when the intended architecture is unavailable, or among other uses, for running multiple copies.
Sandboxing: While some types of sandboxes rely on operating system protections, an interpreter or virtual machine is often used. The actual hardware architecture and the originally intended hardware architecture may or may not be the same. This may seem pointless, except that sandboxes are not compelled to actually execute all the instructions the source code it is processing. In particular, it can refuse to execute code that violates any security constraints it is operating under.[citation needed]
Emulators for running computer software written for obsolete and unavailable hardware on more modern equipment.
See also
- Command-line interpreter
- Compiled language
- Dynamic compilation
- Interpreted language
- Meta-circular evaluator
- Partial evaluation
- Homoiconicity
Notes and references
^ In this sense, the CPU is also an interpreter, of machine instructions.
^ Although this scheme (combining strategy 2 and 3) was used to implement certain BASIC interpreters already in the 1970s, such as the efficient BASIC interpreter of the ABC 80, for instance.
^ Bennett, J. M.; Prinz, D. G.; Woods, M. L. (1952). "Interpretative sub-routines". Proceedings of the ACM National Conference, Toronto..mw-parser-output cite.citation{font-style:inherit}.mw-parser-output q{quotes:"""""""'""'"}.mw-parser-output code.cs1-code{color:inherit;background:inherit;border:inherit;padding:inherit}.mw-parser-output .cs1-lock-free a{background:url("//upload.wikimedia.org/wikipedia/commons/thumb/6/65/Lock-green.svg/9px-Lock-green.svg.png")no-repeat;background-position:right .1em center}.mw-parser-output .cs1-lock-limited a,.mw-parser-output .cs1-lock-registration a{background:url("//upload.wikimedia.org/wikipedia/commons/thumb/d/d6/Lock-gray-alt-2.svg/9px-Lock-gray-alt-2.svg.png")no-repeat;background-position:right .1em center}.mw-parser-output .cs1-lock-subscription a{background:url("//upload.wikimedia.org/wikipedia/commons/thumb/a/aa/Lock-red-alt-2.svg/9px-Lock-red-alt-2.svg.png")no-repeat;background-position:right .1em center}.mw-parser-output .cs1-subscription,.mw-parser-output .cs1-registration{color:#555}.mw-parser-output .cs1-subscription span,.mw-parser-output .cs1-registration span{border-bottom:1px dotted;cursor:help}.mw-parser-output .cs1-hidden-error{display:none;font-size:100%}.mw-parser-output .cs1-visible-error{font-size:100%}.mw-parser-output .cs1-subscription,.mw-parser-output .cs1-registration,.mw-parser-output .cs1-format{font-size:95%}.mw-parser-output .cs1-kern-left,.mw-parser-output .cs1-kern-wl-left{padding-left:0.2em}.mw-parser-output .cs1-kern-right,.mw-parser-output .cs1-kern-wl-right{padding-right:0.2em}
^ According to what reported by Paul Graham in Hackers & Painters, p. 185, McCarthy said: "Steve Russell said, look, why don't I program this eval..., and I said to him, ho, ho, you're confusing theory with practice, this eval is intended for reading, not for computing. But he went ahead and did it. That is, he compiled the eval in my paper into IBM 704 machine code, fixing bug, and then advertised this as a Lisp interpreter, which it certainly was. So at that point Lisp had essentially the form that it has today..."
^ "Why was the first compiler written before the first interpreter?". Ars Technica. Retrieved 9 November 2014.
^ Theodore H. Romer, Dennis Lee, Geoffrey M. Voelker, Alec Wolman, Wayne A. Wong,
Jean-Loup Baer, Brian N. Bershad, and Henry M. Levy, The Structure and Performance of Interpreters]
^ Terence Parr, Johannes Luber, The Difference Between Compilers and Interpreters
^ Kühnel, Claus (1987) [1986]. "4. Kleincomputer - Eigenschaften und Möglichkeiten" [4. Microcomputer - Properties and possibilities]. In Erlekampf, Rainer; Mönk, Hans-Joachim. Mikroelektronik in der Amateurpraxis [Micro-electronics for the practical amateur] (in German) (3 ed.). Berlin: Militärverlag der Deutschen Demokratischen Republik, Leipzig. p. 222. ISBN 3-327-00357-2. 7469332.
^ Heyne, R. (1984). "Basic-Compreter für U880" [BASIC compreter for U880 (Z80)]. radio-fernsehn-elektronik (in German). 1984 (3): 150–152.
^ AST intermediate representations, Lambda the Ultimate forum
^ A Tree-Based Alternative to Java Byte-Codes, Thomas Kistler, Michael Franz
^ Surfin' Safari - Blog Archive » Announcing SquirrelFish. Webkit.org (2008-06-02). Retrieved on 2013-08-10.
^ L. Deutsch, A. Schiffman, Efficient implementation of the Smalltalk-80 system, Proceedings of 11th POPL symposium, 1984.
^ Bondorf, Anders. "Logimix: A self-applicable partial evaluator for Prolog." Logic Program Synthesis and Transformation. Springer, London, 1993. 214-227.
^ Kent, Allen; Williams, James G. (April 5, 1993). Encyclopedia of Computer Science and Technology: Volume 28 - Supplement 13. New York: Marcel Dekker, Inc. ISBN 0-8247-2281-7. Retrieved Jan 17, 2016.
External links
IBM Card Interpreters page at Columbia University
Theoretical Foundations For Practical 'Totally Functional Programming' (Chapter 7 especially) Doctoral dissertation tackling the problem of formalising what is an interpreter
Short animation explaining the key conceptual difference between interpreters and compilers
Major fields of computer science | |
|---|---|
Note: This template roughly follows the 2012 ACM Computing Classification System. | |
| Hardware |
|
| Computer systems organization |
|
| Networks |
|
| Software organization |
|
Software notations and tools |
|
| Software development |
|
| Theory of computation |
|
| Algorithms |
|
| Mathematics of computing |
|
| Information systems |
|
| Security |
|
| Human–computer interaction |
|
| Concurrency |
|
| Artificial intelligence |
|
| Machine learning |
|
| Graphics |
|
| Applied computing |
|
| |
Authority control |
|
|---|


